GestureGPT: Zero-shot Interactive Gesture Understanding and Grounding with Large Language Model Agents
Abstract
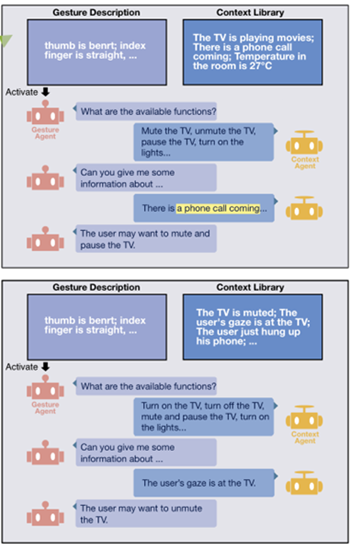
Current gesture recognition systems primarily focus on identifying gestures within a predefined set, leaving a gap in connecting these gestures to interactive GUI elements or system functions (e.g., linking a ’thumb-up’ gesture to a ’like’ button). We introduce GestureGPT, a novel zero-shot gesture understanding and grounding framework leveraging large language models (LLMs). Gesture descriptions are formulated based on hand landmark coordinates from gesture videos and fed into our dual-agent dialogue system. A gesture agent deciphers these descriptions and queries about the interaction context (e.g., interface, history, gaze data), which a context agent organizes and provides. Following iterative exchanges, the gesture agent discerns user intent, grounding it to an interactive function. We validated the gesture description module using public first-view and third-view gesture datasets and tested the whole system in two real-world settings-video streaming and smart home IoT control. The highest zero-shot Top-5 grounding accuracies are 80.11% for video streaming and 90.78% for smart home tasks, showing potential of the new gesture understanding paradigm.